
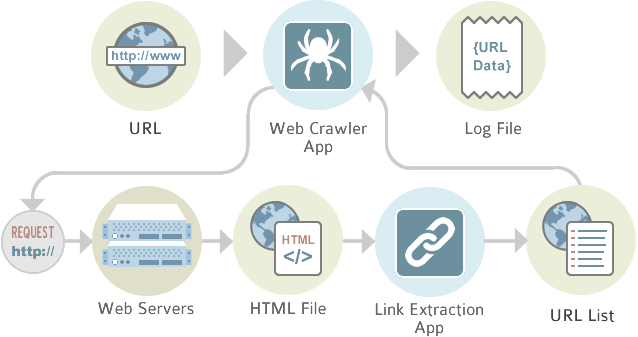
İnternet üzerinde milyarlarca web sayfası bulunmaktadır. Bu sayfaların keşfedilmesi, analiz edilmesi ve arama motoru sonuçlarında gösterilebilmesi için özel yazılım robotları kullanılır. Bu robotlara web crawler adı verilir.
Web crawler’lar, internet sitelerini otomatik olarak ziyaret eden ve sayfa içeriklerini analiz ederek veri toplayan botlardır. Arama motorları bu teknolojiyi kullanarak web sitelerini keşfeder, sayfaları analiz eder ve daha sonra indeksleyerek arama sonuçlarında gösterir.
Bugün kullanılan büyük arama motorlarının tamamı web crawler teknolojisine dayanır. Örneğin:
-
Googlebot
-
Bingbot
-
Yandex Bot
Bu botlar interneti sürekli tarayarak yeni sayfaları keşfeder ve içerikleri analiz eder.
Bu yazıda şunları detaylı şekilde öğreneceksiniz:
-
Web crawler nedir
-
Web crawler nasıl çalışır
-
Arama motorları crawler’ları nasıl kullanır
-
SEO için crawler optimizasyonu
-
Kendi web crawler’ınızı nasıl yapabilirsiniz
-
Web crawling ile web scraping arasındaki fark
-
Crawling teknolojisinin geleceği
Web Crawler Nedir?
Web crawler, internet üzerindeki web sayfalarını otomatik olarak tarayan ve analiz eden yazılım robotudur. Bu botlar web sitelerini ziyaret ederek sayfa içeriklerini inceler, bağlantıları keşfeder ve veri toplar.
Basit bir anlatımla web crawler şu işlemleri yapar:
-
Web sitelerini ziyaret eder
-
Sayfanın HTML içeriğini analiz eder
-
Sayfa içindeki bağlantıları keşfeder
-
Yeni sayfalara geçiş yapar
-
Toplanan verileri kaydeder
Bu sürece web crawling adı verilir.
Web crawler teknolojisi özellikle arama motorları için kritik öneme sahiptir. Çünkü arama motorları interneti bu botlar sayesinde keşfeder.
Web Crawling Nedir?
Web crawling, bir botun internet üzerindeki sayfaları sistematik şekilde taraması işlemidir.
Bu süreç genellikle şu adımlardan oluşur:
-
Başlangıç URL’lerinin belirlenmesi
-
Sayfaların ziyaret edilmesi
-
HTML içeriklerinin analiz edilmesi
-
Yeni bağlantıların keşfedilmesi
-
Tarama listesinin güncellenmesi
Crawler bu döngüyü sürekli tekrar ederek interneti geniş ölçekte tarayabilir.
Arama Motorları Web Crawler Nasıl Kullanır?
Arama motorları interneti keşfetmek için web crawler botları kullanır. Bir web sitesi yayınlandığında arama motorları şu süreci izler:
-
Web crawler siteyi ziyaret eder
-
Sayfanın içeriğini analiz eder
-
Sayfadaki bağlantıları keşfeder
-
Sayfayı arama motoru indeksine ekler
Bu sayede kullanıcılar arama yaptığında ilgili sayfalar sonuçlarda gösterilebilir.
Örneğin Google arama motoru bu işlemi büyük ölçekte gerçekleştirmek için gelişmiş crawler altyapısı kullanır.
Web Crawler Nasıl Çalışır?
Bir web crawler genellikle şu temel bileşenlerden oluşur:
URL Queue (URL Kuyruğu)
Crawler’ın ziyaret edeceği sayfalar burada tutulur.
Fetcher
Web sayfasına HTTP isteği gönderir ve sayfanın içeriğini indirir.
Parser
HTML içeriğini analiz eder ve sayfadaki bağlantıları çıkarır.
Scheduler
Tarama sırasını ve bot hızını kontrol eder.
Storage
Toplanan verileri veri tabanında saklar.
Bu mimari sayesinde crawler botları milyonlarca web sayfasını tarayabilir.
Crawling ve Indexing Arasındaki Fark
Crawling ve indexing kavramları çoğu zaman karıştırılır. Ancak bu iki süreç farklıdır.
Crawling:
Web sayfalarının keşfedilmesi ve analiz edilmesidir.
Indexing:
Sayfanın arama motoru veritabanına eklenmesidir.
Bir sayfa crawler tarafından ziyaret edilebilir ancak şu durumlarda indekslenmeyebilir:
-
noindex etiketi bulunuyorsa
-
robots.txt engellemesi varsa
-
içerik kalitesi düşükse
-
sayfa kopya içerik içeriyorsa
SEO İçin Web Crawler Neden Önemlidir?
Web crawler’ların siteyi doğru şekilde tarayabilmesi SEO açısından kritik bir faktördür.
Crawler dostu bir site şu avantajları sağlar:
-
sayfaların hızlı indekslenmesi
-
yeni içeriklerin hızlı keşfedilmesi
-
site mimarisinin daha iyi analiz edilmesi
-
teknik SEO hatalarının azalması
Crawler botları bir siteyi düzgün tarayamıyorsa içerikler arama motorlarında görünmeyebilir.
Web Crawler Dostu Site Nasıl Yapılır?
SEO açısından crawler dostu bir site oluşturmak için bazı teknik optimizasyonlar yapılmalıdır.
Sitemap Kullanımı
Sitemap dosyası arama motorlarına sitenizdeki sayfaların listesini verir.
Genellikle şu URL’de bulunur:
/sitemap.xml
Sitemap crawler’ların sitenizi daha hızlı keşfetmesine yardımcı olur.
Robots.txt Yapılandırması
Robots.txt dosyası botlara hangi sayfaların taranabileceğini söyler.
Örnek yapı:
User-agent: *
Allow: /
Disallow: /admin
Bu yapı admin panelinin crawler tarafından taranmasını engeller.
Dahili Linkleme
Crawler botları sayfalar arasındaki bağlantıları takip ederek siteyi gezer.
Bu nedenle güçlü bir iç linkleme yapısı oluşturmak önemlidir.
Örnek yapı:
Ana Sayfa → Kategori → Blog Yazısı
Sayfa Hızı
Crawler botları hızlı siteleri daha verimli şekilde tarar.
Site hızını artırmak için:
-
CDN kullanabilirsiniz
-
görselleri optimize edebilirsiniz
-
cache sistemi kullanabilirsiniz
Web Crawler Nasıl Yapılır?
Kendi web crawler’ınızı yapmak oldukça mümkündür. Bunun için en yaygın kullanılan programlama dillerinden biri Python’dur.
Basit bir crawler örneği:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
for link in soup.find_all("a"):
print(link.get("href"))
Bu kod:
-
web sayfasını ziyaret eder
-
sayfa içindeki bağlantıları çıkarır
Daha gelişmiş crawler sistemleri ise bağlantıları takip ederek çok sayıda sayfayı tarayabilir.
Profesyonel Web Crawler Mimarisi
Büyük ölçekli crawler sistemleri daha gelişmiş bir mimari kullanır.
Bu mimari genellikle şu bileşenlerden oluşur:
-
URL frontier sistemi
-
dağıtık crawler worker’ları
-
veri depolama sistemi
-
hata yönetimi
-
hız kontrol mekanizması
Bu yapı sayesinde crawler botları milyonlarca sayfayı tarayabilir.
Web Crawling ve Web Scraping Arasındaki Fark
Web crawling ve web scraping birbirine yakın kavramlardır ancak farklı amaçlara sahiptir.
Web Crawling
Siteleri keşfetmek için kullanılır.
Web Scraping
Sayfa içinden belirli verileri çekmek için kullanılır.
Genellikle scraping işlemi crawler sistemi üzerine kurulur.
Web Crawler Kullanım Alanları
Crawler teknolojisi birçok farklı alanda kullanılmaktadır.
Arama Motorları
Web sitelerini keşfetmek için crawler kullanır.
SEO Araçları
SEO araçları siteleri analiz etmek için crawler kullanır.
Örneğin:
-
Ahrefs
-
Screaming Frog SEO Spider
-
Semrush
Veri Analizi
Crawler botları büyük veri toplamak için kullanılabilir.
Pazar Araştırması
Rakip analizleri için crawler sistemleri kullanılabilir.
Web Crawler Geliştirirken Dikkat Edilmesi Gerekenler
Crawler geliştirirken bazı kurallara dikkat edilmelidir.
Robots.txt Kurallarına Uyma
Crawler botları sitelerin robots.txt dosyasına saygı göstermelidir.
Rate Limiting
Sunuculara aşırı istek gönderilmemelidir.
User-Agent Tanımlama
Crawler botu kendini tanıtmalıdır.
Örnek:
User-Agent: MyCrawlerBot
Web Crawler Engelleme Yöntemleri
Bazı siteler crawler botlarını engellemek isteyebilir.
Bunun için şu yöntemler kullanılabilir:
-
robots.txt
-
firewall kuralları
-
IP engelleme
-
captcha sistemleri
Ancak arama motoru crawler’larını engellemek SEO açısından önerilmez.
Web Crawler Teknolojisinin Geleceği
Web crawler teknolojisi günümüzde hızla gelişmektedir. Özellikle yapay zeka destekli crawler sistemleri ortaya çıkmaktadır.
Yeni nesil crawler’lar şunları analiz edebilir:
-
içerik kalitesi
-
kullanıcı deneyimi
-
sayfa performansı
-
spam içerikler
Bu gelişmeler arama motorlarının daha akıllı indeksleme sistemleri kurmasına yardımcı olmaktadır.
Sonuç
Web crawler teknolojisi internetin temel yapı taşlarından biridir. Arama motorları interneti keşfetmek ve içerikleri analiz etmek için crawler botları kullanır.
Bir web sitesinin SEO performansını artırmak için crawler dostu bir yapı oluşturmak büyük önem taşır.
Özetle:
-
Web crawler internet sayfalarını tarayan botlardır
-
Crawling sayfaların keşfedilmesini sağlar
-
Indexing sayfaların arama motoruna eklenmesidir
-
SEO için crawler dostu site mimarisi gereklidir
Web crawler mantığını anlamak hem geliştiriciler hem de SEO uzmanları için büyük avantaj sağlar.




Yorum Yap
Yorumlar (0)
Henüz yorum yapılmamış. İlk yorumu siz yapın!